
Replication — Distributed Systems
An Essential Tool for Fault Tolerance

As more interdependent pieces are introduced into your system, more things can go wrong.
What happens if your database goes down? What happens if your network goes down? What happens if a ton of requests suddenly flood your servers?
Lucky for us, the great system designers of history have developed tools to handle these edge cases.
The most important of those tools is replication.
Replication is keeping a copy of the same data on several machines.
What are the benefits of keeping multiple copies of the same data?
High Availability
Data is still available if one machine experiences hardware faults.
Every software engineer has nightmares about their database going down. If we keep a backup copy (or copies) of the data, we can spin up a new database in case of emergency.
No more nightmares!
Disconnected operation
This is how offline editing in Google Docs works.
If a machine goes offline, but has a local copy of the data, it can keep functioning without access to the network. Then when a network connection is restored, simply push local updates to the rest of the system.
Lower latency across geographies
If data is only stored in the US, your international users will experience slow loading times. Their requests will have to travel across the globe and back to retrieve data.
By storing data copies in multiple regions, request latency will come down for those users.
Scalability for reads
When your traffic begins to grow, your system will experience a heavy burden. To relieve some of this burden, we can redirect read and write requests to go to separate machines. Store copies of the data among many machines, and distribute reads among those machines.
Now the system can return results to your users while experiencing much less load.
Now that we know the benefits of replication. How does it work behind the scenes?
There are 2 design choices to consider when thinking about replication— the model, and the synchronicity.
There are 3 replication models:
Single-leader replication
Clients (your users) send writes to a single node, the leader. The leader streams data changes to its followers (the replicas). Replicas pick up the stream and update their copy of the data.
The upside: This model is easy to manage. No conflict resolution is needed between nodes.
But, reads from some replicas might be stale while the data changes propagate from leader to followers.
Multi-leader replication
Clients send writes to one of several leaders. Leaders send data changes to each other and the replicas.
Leaderless replication
Clients send writes to several nodes, and read from several nodes in parallel. Clients try to detect and correct nodes with stale data.
The more leaders are present in a system, the harder it is to understand the system. The replication schemes in 2) and 3) can sometimes have unintuitive behaviors. However, more leaders make the system robust to failure.
Then there’s the question of Synchronous vs Asynchronous replication. Should the leader wait for a receipt confirmation from replicas?
Synchronous replication waits for a confirmation from the followers after every write. It is more consistent, so client reads have a stronger guarantee of being up to date.
But. If a replica fails the whole system is blocked, since the leader never gets a reply.
Asynchronous replication is fast. It writes and assumes followers receive all data. But there arises a serious problem: replication lag.
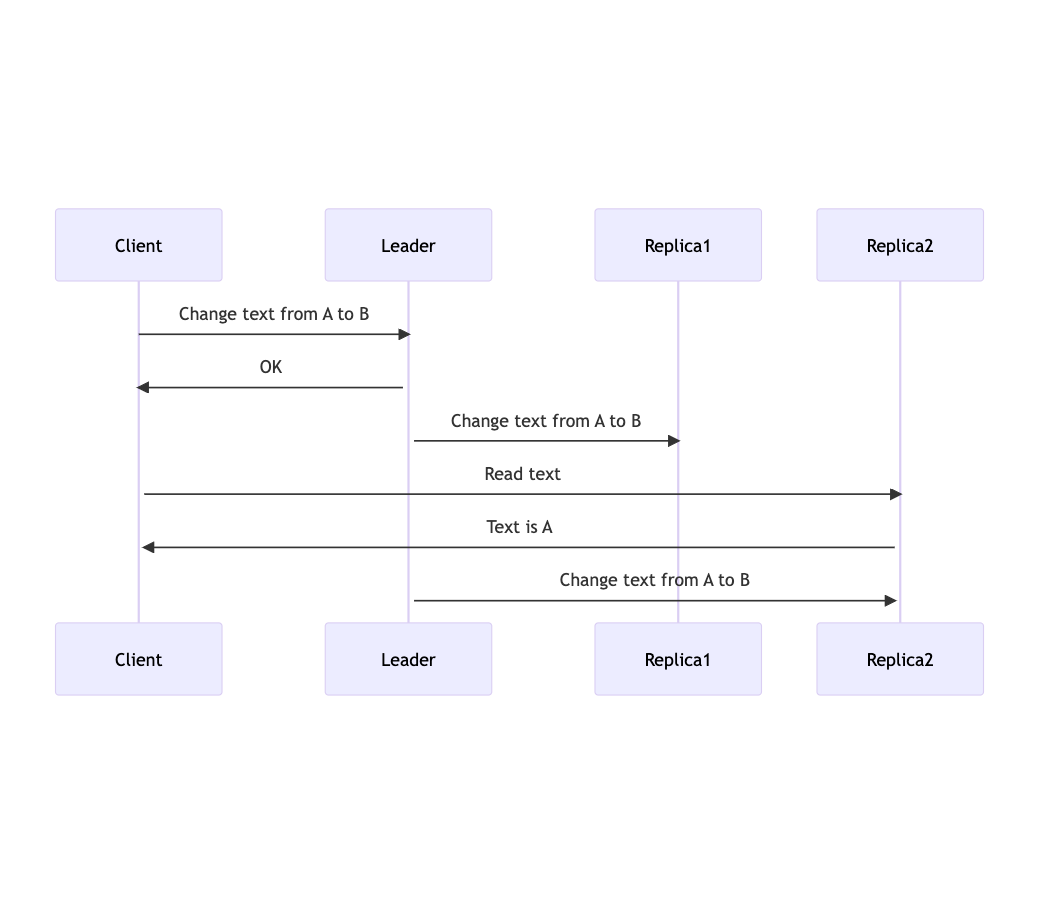
The client reads from replica2 before the leader had a chance to update replica2.
How to deal with replication lag?
There are a few models for handling replication lag:
Read after write consistency
Users always see data they submitted themselves.
The idea here is for some time after the user writes, read from the leader. The leader always has the most up-to-date copy of the data, so it is guaranteed to show the latest write.
Monotonic Reads
After users have seen data at a point in time, they shouldn’t later see data from before that point in time.
This is an edge case of replication lag, where a user reads from a fresh replica and then a stale replica. So they see new data and then an old version of the data.
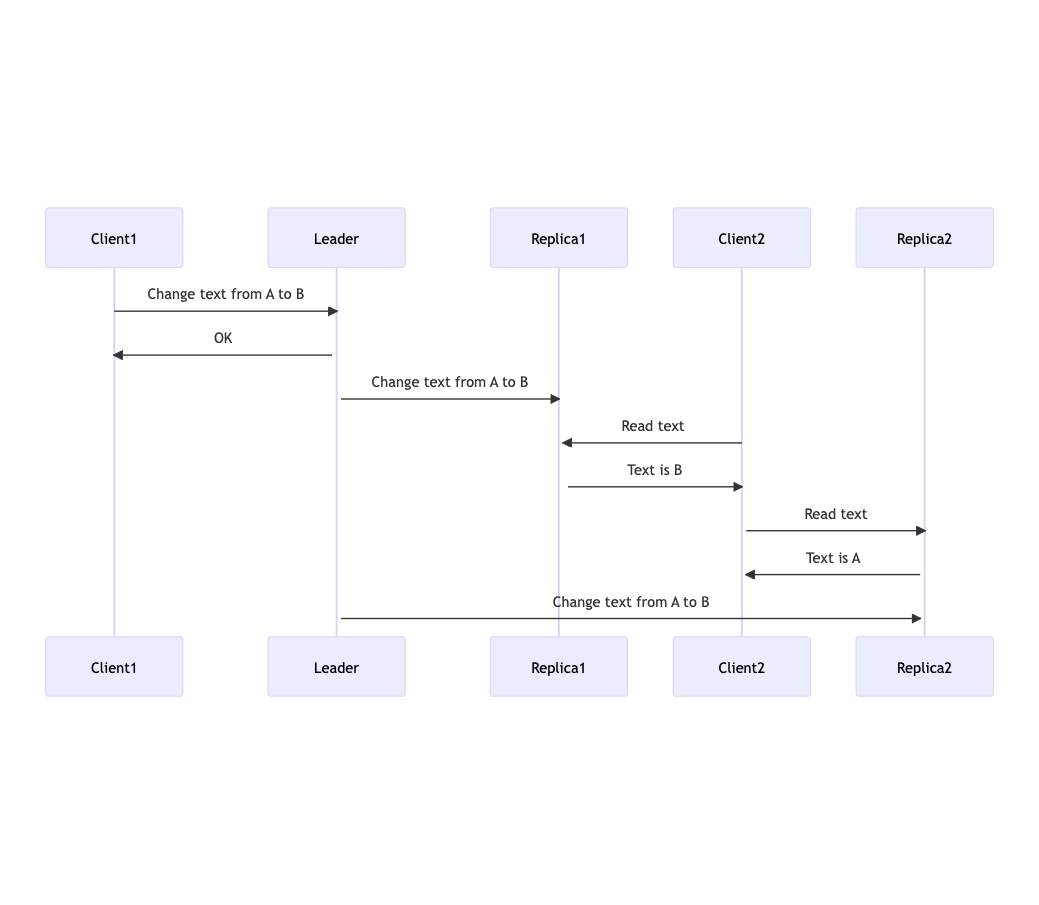
To ensure users never “travel backwards in time”, a system assigns each user a dedicated replica. Since every request goes to the same replica, stale data can never be shown after fresh data.
Takeaways
Replication is a great tool to have in your arsenal. It’s used in every distributed system for scalability and resilience.
The main tradeoff in leader selection is between simplicity and robustness.
The more leaders your replication model has, the more robust. But more edge cases to consider.
The main tradeoff of synchronous vs asynchronous replication is between consistency and robustness.
Synchronous guarantees fresh data on all replicas. But if one replica goes down, your system is bricked.
The biggest pain point with replication is replication lag, where updates take a long time to propagate from leader(s) to followers.
You probably don’t want to think about all the edge cases of replication lag. Writes in a distributed system should “just work”.
That’s where transactions are handy, the topic of next week’s substack. They are a useful abstraction that handle the problem of inconsistent writes.
Hope this was useful. Until next time.
Cheers,
Capt’