
Transactions — Distributed Systems
The Guardian of your Data

Last week we looked into one method of fault tolerance— replication. To reduce our application’s fragility, it makes sense to store multiple copies of data.
But that introduces a new set of problems. How do we keep all these copies consistent with each other? When your application spans across multiple machines, the data can encounter multiple machines reading and writing to it at the same time. This is known as concurrency.
Transactions are an abstraction to deal with concurrency. They group several reads and writes into one logical unit.
Concurrency issues are also known as race conditions. They typically occur when one process reads data that is simultaneously modified by another process. Or, when two processes try to modify the same data at the same time.
The common belief among software engineers is that ACID databases (often referring to relational databases) protect against all concurrency issues. The truth is more nuanced— all databases, even ACID databases, provide varying levels of protection against concurrency.
Only by understanding the concurrency edge cases in distributed systems can we prevent them. Your Postgres database can’t save you.
Let’s explore some race conditions.
Dirty reads
Transaction 1 reads Transaction 2’s writes before Transaction 2 has completed.
Dirty writes
Transaction 1 overwrites Transaction 2’s writes before Transaction 2 has completed.
A database that prevents the above race conditions has read committed isolation. This is a common feature in relational databases like Postgres and SQL Server.
Non-Repeatable Reads
Client sees different parts of the database at different points in time.
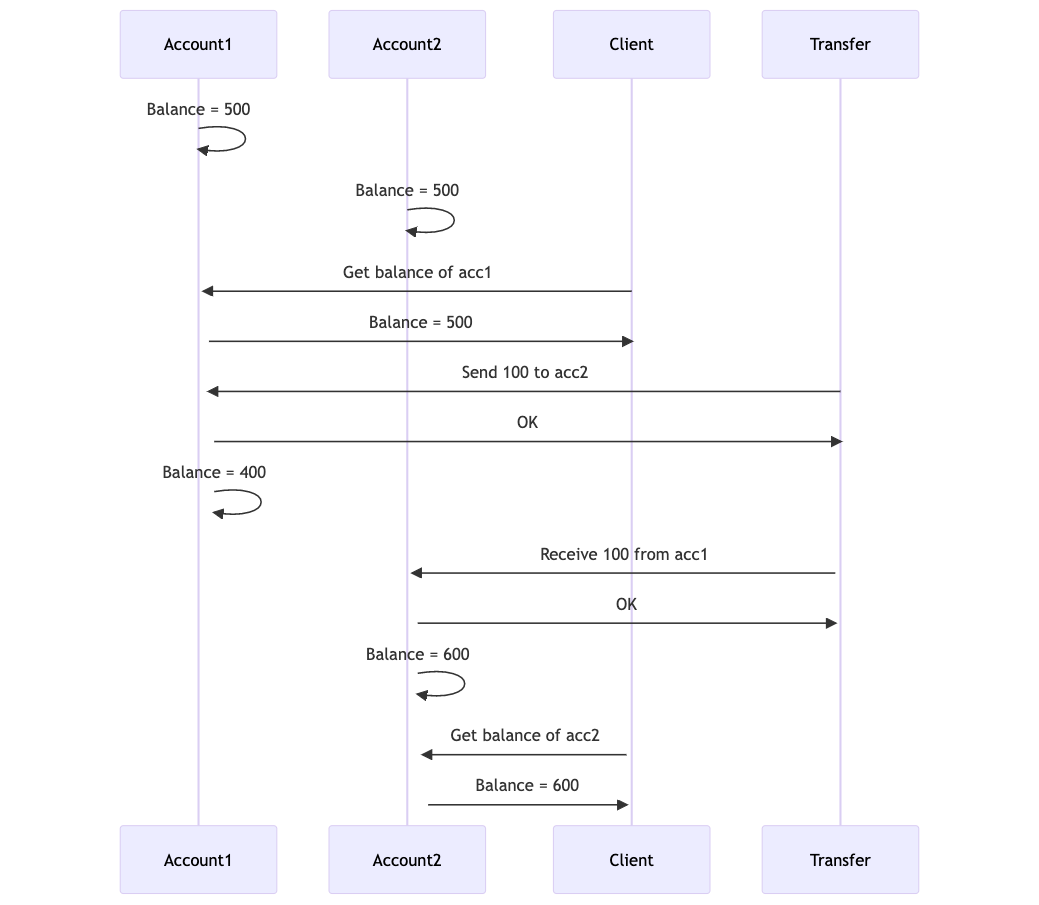
Client starts with $500 in Account1 and $500 in Account2.
Client checks Account1, which shows $500. Client checks Account2, which shows $600. Huh??
Due to bad timing, it looks like the client has gained $100 from thin air!
If Account1 was queried again, it would read $400.
While the example shown is not a system-breaking problem. The same thing could happen during a long-running analytics query, which would skew the results.
To prevent non-repeatable reads, databases use snapshot isolation. Another common feature of relational databases.
Each transaction reads from a consistent snapshot of the database. If Transaction 1 is reading, and Transaction 2 modifies the data, Transaction 1 only sees the old data.
Very useful for long-running analytics queries.
Lost updates
This happens when two transactions read, modify, and write the same value simultaneously. In the example below, two users get the current value of Counter, add 100, and write back. The expected result is 700, since two users both added 100 to Counter.
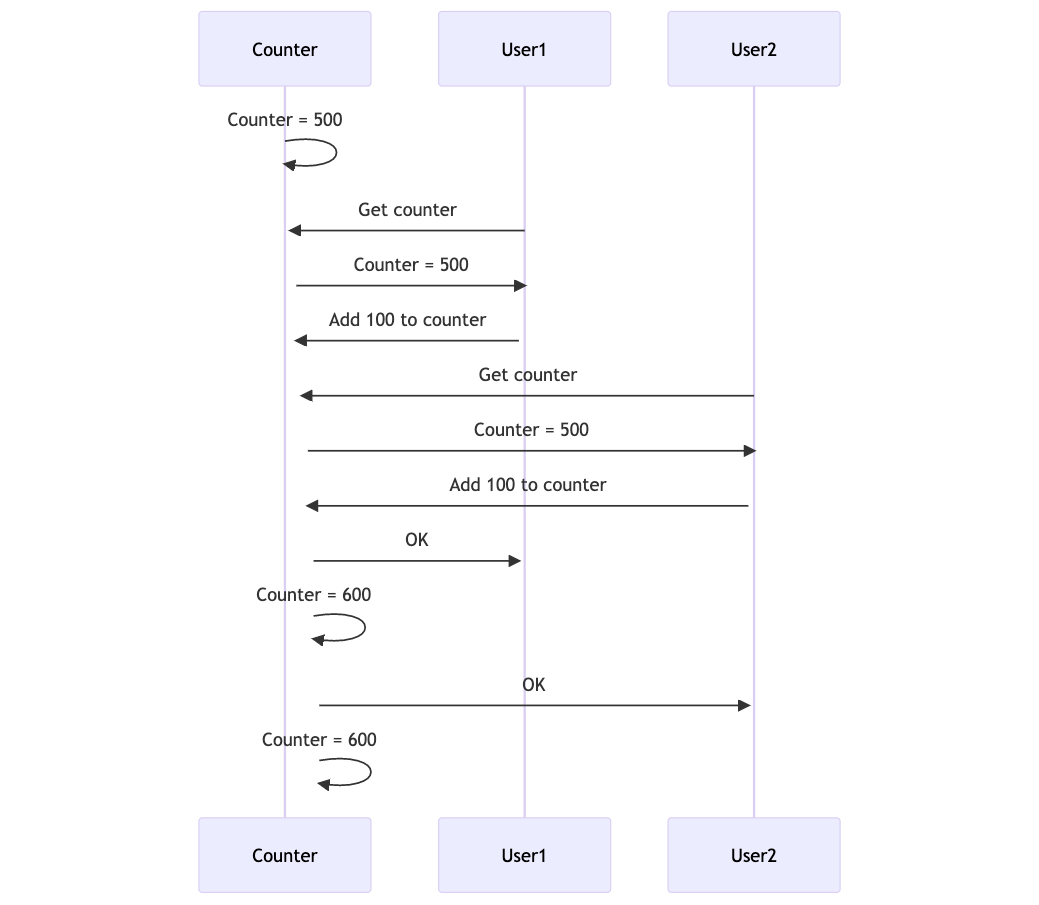
The write by User1 was lost, overwritten by User2.
A solution for this is locking. When a row is read, it is locked so that no other transaction can read it until the update has been completed.
The above race conditions have mechanisms built in to databases to prevent them. But the next one is subtle, and not so easy to detect.
Write skew
A lost update, but on two separate objects.
Suppose your system manages an oncall shift at a hospital.
At any given time, at least one doctor must be oncall. Doctors can request to be taken off the shift if they’re sick.
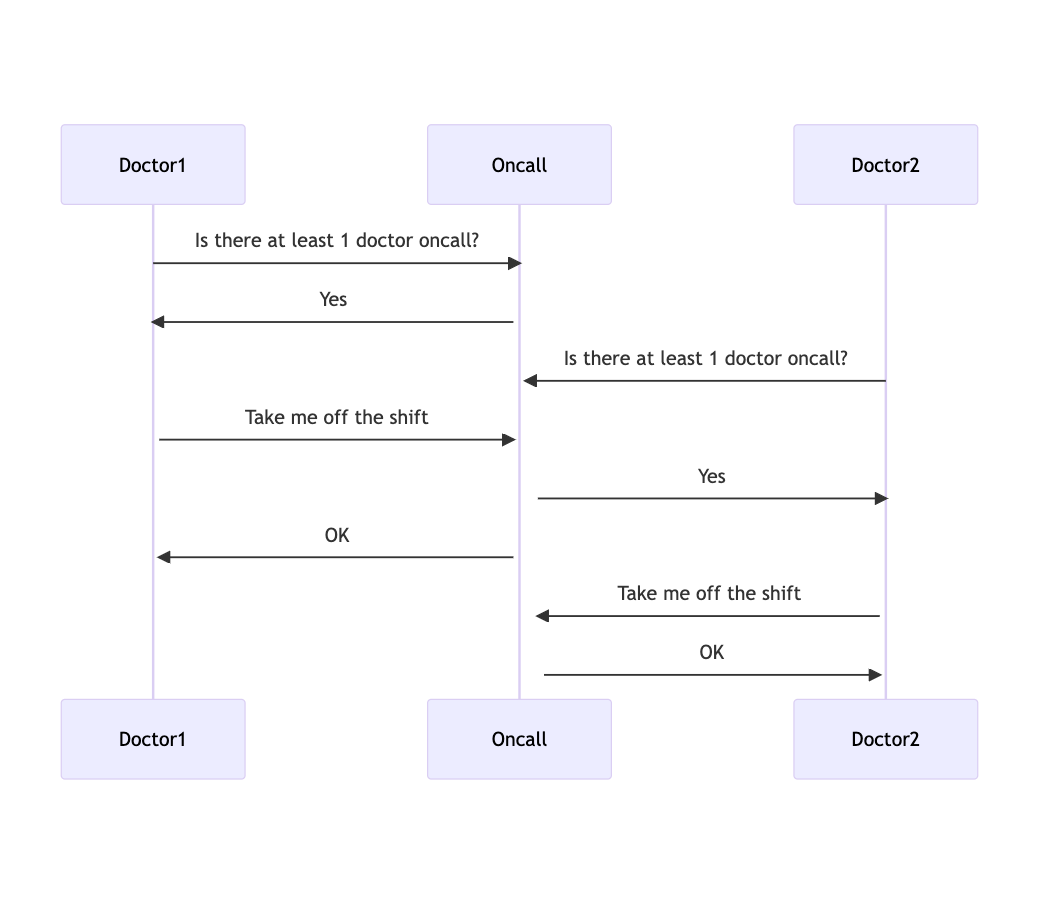
So your transaction looks like:
Doctor1 queries database to check if at least 1 doctor is oncall
If yes, update Doctor1’s shift to no longer be oncall
If no, reject request
In this case, if two doctors request to be taken off shift at the same time, there are no longer any doctors oncall!
Snapshot isolation doesn’t help, since it would show the data before any updates.
Locking doesn’t help, as the rows for Doctor1 and Doctor2 are separate.
How can our application prevent problems like write skews that arise with concurrency?
Well, the answer sounds simple. Remove the concurrency!
Make our transactions serializable. In other words, have concurrent transactions execute one after the other.
A few ways to do this:
Literally executing transactions in serial order
Each transaction has an exclusive lock on the entire database. It is simple and does the trick for smaller applications. But this does not scale well.
Two-phase locking (2PL)
Each transaction has an exclusive lock on part of the database. If a lock is held by another transaction, wait until it’s released before starting the next transaction.
This still doesn’t perform well, since there’s so much overhead of acquiring and releasing locks. But, the behavior of 2PL is straightforward to reason about.
Serializable Snapshot Isolation (SSI)
Transactions operate on a snapshot of the database. If two transactions write to the same object and data is corrupted, abort one of the transactions and retry.
Transactions are non-blocking so performance tends to be stronger. But, SSI introduces complexity. The database is operating on multiple versions at once, which also increases overhead.
Takeaways
If your application requires strong consistency guarantees, it’s worth thinking through the various race conditions.
A common tradeoff in distributed systems is simplicity vs performance, and that holds true when it comes to handling concurrency.
If you’re enjoying these technical deep dives, let me know in the comments below. My DM’s are also open on Twitter.
Happy architecting.
Cheers,
Capt’